Using AI for green procurement

Government procurement is estimated to be responsible for 15% of all greenhouse gas emissions, according to a report by Boston Consulting Group and the World Economic Forum. The same study found that about 40% of all emissions related to government procurement could be mitigated for less than US$15 per ton of CO2 emissions. If we want to tackle climate change, and if we want to have greener, cleaner, and more resilient supply chains, governments will need to buy things in a fundamentally different way. Introducing more sustainable procurement policies and processes presents an enormous opportunity for public authorities to not only contribute to reaching carbon emission reduction goals but also to drive sustainable societal and economic development.
Yet, many governments have not introduced policies and procedures for buying greener and even where it is possible to use green criteria for purchasing, many procurement officers are unsure of how to include them. Therefore, following discussions at the ISF EU Hackathon last year, we wondered if AI could assist us in identifying green requirements in real procurement documents based on a predefined list of recommended green requirements. So with a grant from Schmidt Futures, we set out to build a proof of concept for our “Green Cure” AI tool.
In this post as part of our series exploring the impact of AI on public procurement, we’ll outline our approach and lessons learned. You can also explore our open-source code on GitHub.
Why we prioritized furniture procurement
We wanted to test our approach on one product category that governments buy regularly and that, in the EU, have clearly defined green requirements designed to reduce the environmental impact of a purchase.
To find the most appropriate product, we reviewed the EU’s Green Public Procurement Criteria and Requirements, which cover 14 product groups (such as computers, food catering services, cleaning services, and so on). But the EU’s procurement notices use the Common Procurement Vocabulary (CPV), not these product groups, so we had to match the product groups to CPV codes (see our spreadsheet). We looked for others who had performed a similar matching, in order to compare and validate our matches, and found the matching performed by ProZorro, the central public procurement system of Ukraine, which was consistent with ours.
EU Member States must publish their procurement notices to Tenders Electronic Daily (TED), so we used TED data to rank the product groups by number of procurement notices, to produce a shortlist of product groups to investigate.
After consultations with the Lithuanian Public Procurement Agency, one of the most advanced publishers of green procurement data in the region, we chose the Furniture (39100000-3 and sub-codes) product category. It is regularly procured across Europe and its green requirements are well documented by the EU.
Defining our green requirements
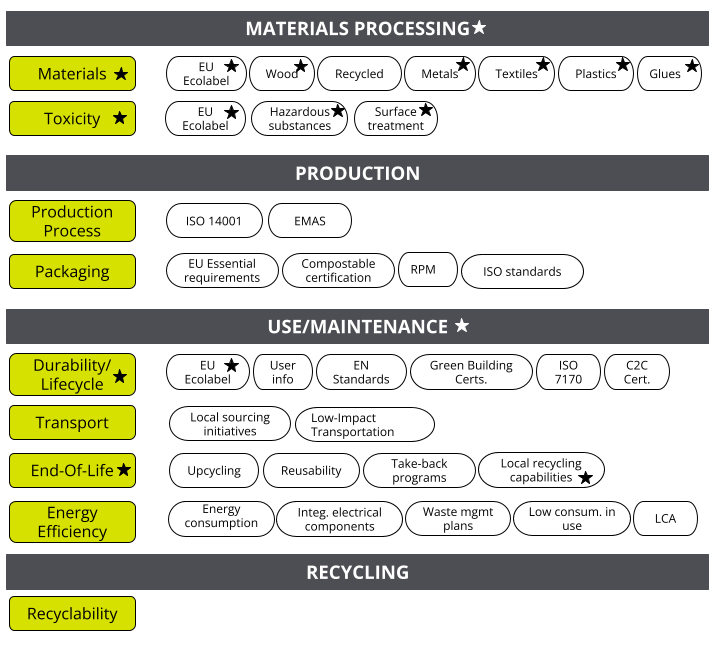
We developed a 3-level structure for green requirements. The top level covers the four product lifecycle stages of materials processing, production, use/maintenance, and recycling. For each product lifecycle stage, we explored how well ChatGPT could identify factors (for example, the stage “materials processing” has the factors “materials” and “toxicity”). For each of these factors, we listed requirements (like sustainable wood) and certifications (from Forest Stewardship Council, ISO, Ecolabel, etc.).
These were refined into simple sentences to express the green requirements. Using ChatGPT, we also identified 10 keywords for a sample of the green requirements, for matching purposes. Throughout this process, we developed prompts that produced decent responses by trial and error.
Finally, we verified the correctness of these green requirements against public sources, and we compared these green requirements against those of the EU. Almost all requirements in the materials processing stage matched, and a few requirements in use/maintenance stage matched. As we discuss below, our analysis revealed opportunities to improve the EU’s green requirements for furniture as well as insights on how countries and regulators are expressing green criteria.
Our pilot therefore shows promise for using AI to assist analysts in identifying green requirements. As future work, our sequence of prompts can be automated using Open AI’s Chat APIs, to assist analysts in more quickly collecting information for review.
Choosing procurement documents to analyze
Once we had our green criteria expressed as simple phrases, it was time to match them against real procurement documents.
After exploring different options (and, unfortunately, discovering that we wouldn’t be able to use Lithuania’s data as expected for access reasons), we chose to examine procurement notices from the EU published on Tenders Electronic Daily (TED) and green purchases from the Dominican Republic.
We downloaded, converted, and cleaned the source data (TED notices, Dominican specifications, and EU green requirements) to produce texts. We split the texts into sentences using Punkt Tokenizer Models from NLTK, since the EU uses 27 languages, and also since a naive approach can be sensitive to abbreviations, parentheticals, etc. The sentences from the TED notices and Dominican specifications formed the “corpus” (or input data) that we later searched for green requirements. The sentences from the EU green requirements were used as the “queries” to search the TED notices. Sentences expressing green requirements were manually sampled from the Dominican specifications and were used as the queries.
Running the semantic search
Once we had the corpus and queries as sentences, we implemented semantic search. We used sentence transformers to run the semantic search and to interface with Hugging Face, which provides models and datasets for natural language processing, especially. We chose a model that performed best with our rather technical procurement-related text in 27 languages: paraphrase-multilingual-MiniLM-L12-v2. (For more on our technical approach, see our gentle introduction to applying AI in procurement.)
While the model performed well enough, it is not ideal for the procurement context.
When choosing a model, it’s important to understand its training data. A bad choice is how you end up with Google AI Overviews training in Reddit answers and suggesting you add glue to your pizza and eat one small rock per day.
The model we used is described in Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks, which states: “We train SBERT on the combination of the SNLI (Bowman et al., 2015) and the Multi-Genre NLI (Williams et al., 2018) dataset. The SNLI is a collection of 570,000 sentence pairs annotated with the labels contradiction, entailment, and neutral. MultiNLI contains 430,000 sentence pairs and covers a range of genres of spoken and written text.”
SNLI is composed of Flickr image captions. Multi-Genre NLI is composed of a wide range of American English, including: in-person and telephone conversations from the 1990s and 2000s; reports, speeches, letters, and press releases from government websites; 10 fiction books across five genres; five non-fiction works on the textile industry and child development; Slate Magazine articles; and Berlitz travel guides.
These texts are quite different from procurement notices. Indeed, whenever you interact with a generally available LLM, you are similarly interacting with a model that was trained on datasets that might be very far from your specific interest.
That said, the labels (contradiction, entailment, and neutral) are relevant to comparing the meaning of sentence pairs, allowing the model to perform well enough.
Preparing better datasets that are more specific to procurement would be a major project. To our knowledge, large datasets of labeled sentences about procurement do not exist yet. More detail on the work involved is described in the linked papers – but, in short, it involves people comparing and annotating hundreds of thousands of sentences.
What we discovered
When we compared the green requirements we developed using AI with the EU’s green criteria for furniture, we found the EU’s criteria have substantial gaps and miss many opportunities to make furniture procurement greener, such as:
- Use of recycled content during production;
- Environmental impact during the production process;
- Green requirements for packaging;
- User information on how to extend product durability;
- Green requirements for the means of transportation;
- Upscalability;
- Take-back-programs;
- Waste-management plans;
- Energy-efficiency (for furniture items that use energy, like adjustable desks);
- Recyclability.
We learned that – with a human in the loop to control for “hallucinations” and errors – an LLM can be an effective information access system for green requirements.
We also learned a lot about how countries use green criteria (and how much), and how regulators express green criteria.
Align policy and practice: There is a significant mismatch between the language used in the EU’s Green Public Procurement Criteria and Requirements and the language used in procurement notices. The regulatory text is more technical, academic and precise: for example, it has paragraphs about testing latex foams by passing filtrates through membranes and using spectrometry to examine the content of heavy metals. On the other hand, procurement notices refer to certifications like “EuroLatex ECO-Standard” or “CertiPur”. Regulators can better promote green procurement by sharing guidance in simpler language that can more readily be reused in procurement notices (and understood by potential suppliers).
Use standardized requirements: Electronic catalogs and product templates lead to standardizing the language of green requirements, which can make it easier for suppliers to understand, anticipate and fulfill the government’s needs. In fact, we deliberately did not use procurement data from Peru for this experiment because the green requirements are standardized and so easy to identify that using AI would be redundant. This is because in Peru, green purchases are made using electronic catalogs for some products, like paper, printer toner, and air conditioning. These catalogs use product templates in which the green requirements use standardized wording. In other jurisdictions, there is much greater variation in how green requirements are expressed, which might reduce the efficiency and effectiveness of the market.
Simplify criteria: Green requirements do not need to be complicated sentences. In most cases, it is sufficient to defer the complexity to a certification, like FSC, or to use a simple word, like “biodegradable” or “energy-efficient.” This would simplify our task, as it would become a simple keyword search, rather than multilingual sentence similarity. Instead of trying to shape the market by expressing complicated requirements in procurement notices, governments can participate in establishing new certifications, like the ecolabel programs backed by the US Environmental Protection Agency (EPA). The private sector can then aim to satisfy a stable certification, rather than unpredictable requirements.
Publish more, high-quality data: We also had the opportunity to practice new AI techniques, and to learn the limitations of available public procurement data. In the Dominican Republic, only 290 purchases could be analyzed. In the EU, the TED data was somewhat incomplete; for example, in 2022, about 75% of the 7,817 procurement notices contained technical criteria (the rest expressed these criteria in separate documents that would have needed to be downloaded from individual procurement authority’s websites), and only about 50% contained non-price award criteria. With richer data, we would be able to describe in greater detail the opportunities and limitations of applying AI techniques to procurement data. At present, the low adoption of green criteria is the main barrier.

What’s next
Since we conducted this project, OpenAI has released new embedding models. It could be interesting to redo the tests and compare their performance against the Hugging Face models we used originally. Amazon updated its Titan Text Embeddings models in April too. Hugging Face has also made it simpler to fine tune models, such that we can improve the performance of the semantic search – without authoring a new model from scratch.
Based on what we learned about the maturity and cost of the technologies and about government buyers’ readiness and interest in applying these technologies, before exploring a full tool, we are waiting to see greater adoption of green criteria by government buyers, and better publication of their tender documentation as machine-readable data – ideally with labeling of green procurements in the e-procurement systems, to assist with AI training). We will continue to monitor developments and experiment with new technologies, as we pursue other promising opportunities for impact in the field of open and sustainable procurement.